Presentation on the ELPUB 2009 conference in Milan about Persistent Identifiers in the Knowledge Exchange context.
Blog
-
Silicon Valley effect for Innovating Research itself
This presentation is about thinking how we can create an environment or culture in the academic landscape that enables all the knowledge and expertise of the individuals in the research community as a whole to reach a better networkeffect for innovative research projects.
-
Modern Surgery – Fidling in a Holographic brain, let robots do the actual work
Heb niet een video kunnen vinden over dit onderwerp, ik denk dat ik het uit de BBC Science heb of The Economist die ik afgelopen week heb gelezen.
Video’s die het onderwerp benaderen zijn hier te vinden. De logische link tussen beide technieken is een kleine stap verwijderd van elkaar.
Holographic optics:
http://nanotechnologytoday.blogspot.com/2008/02/ua-optical-scientists-add-new-practical.htmlRobot surgery:
Artikel over de combinatie van die twee:
http://www.thefreelibrary.com/Digital+Holography+Speeds+Surgery+and+Surgical+Planning;+Brain,…-a018716228Over tools voor onderzoekersgesproken, dit zijn dure speeltjes…
-
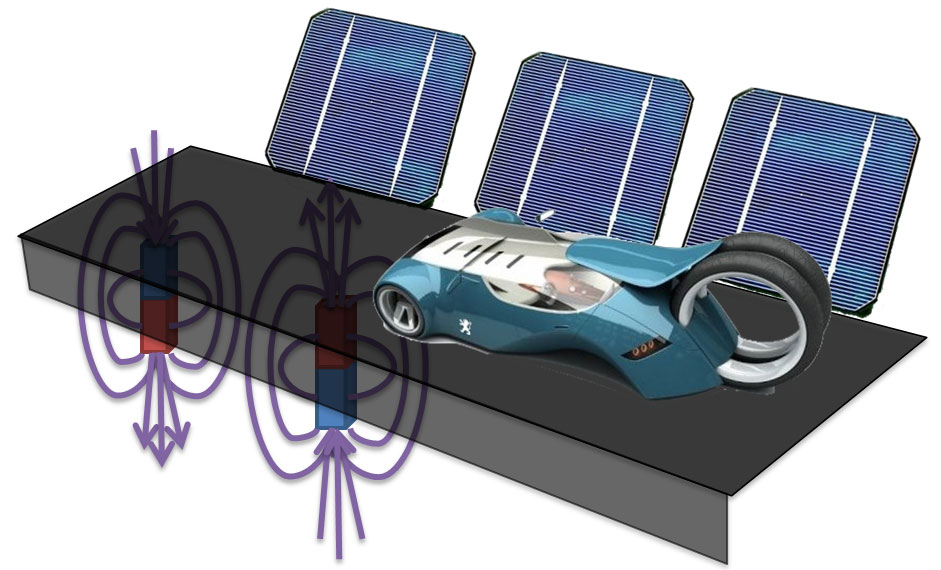
Electric car induction powered road infrastructures
 Ok here is the thing. I read the briefing acticle “The electrification of motorisation” (with subtitle: “The electric-fuel-trade acid test”) in The Economist of September 5th-11th 2009, on page 73. I was excited and thrilled to read this article in the hope they could provide me with new information about this subject. Since it is The Economist wiriting, it is ofcourse about the Joule per dollar one can get out of a gas or electrical battery. The thesis continues about the bateries, new developments make Li-ion bateries faster to charge, nanotubes to give the electrones a smooth ride. etc. Then they talk about the infrastructure to recharge and to increase the range of your car. There are mentioned two possibilities: 1. charging station at fuel stations, charging a highspeed (and very expensive) battery for 80% in 30 minutes. 2. swapping stations that replace the depleted battery with a new one (see also the TED talk of Shai Agassi) .
Ok here is the thing. I read the briefing acticle “The electrification of motorisation” (with subtitle: “The electric-fuel-trade acid test”) in The Economist of September 5th-11th 2009, on page 73. I was excited and thrilled to read this article in the hope they could provide me with new information about this subject. Since it is The Economist wiriting, it is ofcourse about the Joule per dollar one can get out of a gas or electrical battery. The thesis continues about the bateries, new developments make Li-ion bateries faster to charge, nanotubes to give the electrones a smooth ride. etc. Then they talk about the infrastructure to recharge and to increase the range of your car. There are mentioned two possibilities: 1. charging station at fuel stations, charging a highspeed (and very expensive) battery for 80% in 30 minutes. 2. swapping stations that replace the depleted battery with a new one (see also the TED talk of Shai Agassi) . -
innovation by watching evolution
Nature has come-up with elegant solutions of today’s problems.
Janine Benyus tells us about a research field that is called Biomimicry. In this field they look at strategies nature has come-up with to solve different problems, just by trail and error during the process of evolution. Let evolution work for us. www.asknature.org is a website one can post different strategies that can be used by humans to solve problems of teoday in an elegant and natural way that keeps the planet eurth in its equilibrium.
Besides that one can innovate just by changing perspective. This talk is about the evolutionary perspective of grass.
This talk is about the aquatic-ape. A different perspective on the evolution of the homo sapience.
-
Incentives for innovation, based on intrinsic motivation
Dan Pink spoke on TED.com about the way traditional businesses are build is often still with the old mindset from the industrial era using incentives like the “carrot and the stick” model to increase production performance. However for more complex tasks people get paralysed when put under pressure to perform by higher rewards. Rewarding systems work better when the task is simple and the details are well scripted, like in repetitive manufacturing work.
In this clip he explains the concept, and the statistics behind it.
Since I am working at SURFfoundation, I have noticed the same behaviour. People do not want to finish a project because of the large amount of money you put in to it, but because of the intrinsic motivation and a high level of autonomy. SURFfoundation subsidises innovative research projects, half paid by SURF, the other half by universities, but even on an unbalanced budgets (say 20% SURF, 80% universities), people are prepared to step in the project. Even when there is no money incentive at all, they want to work together with different universities to tackle a problem, because their intrinsic motivation is high. The only thing SURFfoundation has to do is to facilitate cooperation infrastructure (meeting rooms and synchronising agenda’s).
Daniel Pink points out that for higher performance on complex tasks the business model should thrive on intrinsic motivation. The elements that create intrinsic motivation are, according to Daniel Pink: Autonomy, Mastery and Purpose. This results in a completely new business model, abbreviated by ROWE (Results Only Work Environment).

-
New ways of innovation in the Higher Education and Research in the Netherlands
Below you will find a thesis I have witten for the MasterClass course Innovation Management. This thesis is about how SURFfoundation (the organisation I work for) can improve the commitment of innovation of every employee throughout the organisation of every single University and Research institute that is a member of SURFfoundation.
Unfortunately for the English readers, this has been written in Dutch. For the Dutch readers, enjoy reading! 🙂
There is a Disclaimer: this thesis is only fictional, and does not reflect the way SURFfoundation is moving ahead in the future. So no rights or claims can be made or what so ever based on this thesis written below.
New ways for SURFfoundation to innovate in the Dutch Higher Education and Research field (in Dutch)
-
Elaine Morgan says we evolved from aquatic apes
Elaine Morgan is a tenacious proponent of the aquatic ape hypothesis: the idea that humans evolved from primate ancestors who dwelt in watery habitats. Hear her spirited defense of the idea — and her theory on why mainstream science doesn’t take it seriously.
Elaine Morgan is an octogenarian scientist, armed with an arsenal of television writing credits and feminist instincts, on a mission to prove humans evolved in water.
-

International Repositories Infrastructure Workshop – Persistent Identifiers

This week I attend the International Repositories Infrastructure Workshop (This workshop was sponsored by JISC, DRIVER and SURFfoundation) The goal of the workshop was to identify shared agendas for action and coordination between major national and international stakeholders, for the purpose of developing an international federated network of repositories.
Other blogs about this event can be found here http://digitallibrarian.org/?p=44 and here http://digitalcuration.blogspot.com/2009/03/international-repositories.html . Tweets which have been uttered can be found here http://twitter.com/search?q=#repinf09
In this blog I will write about Identifiers, and the Identifier workshop I have attended in.
The Identifier workshop was chaired by Andrew Treloar (Australia, ANDS project) and he did a great job in bringing consensus to the group. First of all we have to accept that many identifier systems already exist, and that no-one is planning on abandoning their beautifully build identification mechanisms. However when talking about reliable interoperable infrastructures for serving scholarly communication work flows, we have to be able to communicate across the silo’s we’ve beautifully have crafted. In the workshop we came to the conclusion that what we need in scholarly communication work flows is not yet-another-identification-mechanism, but a meta service that builds bridges across these identifier mechanisms. A similarity/equivalence service is highly recommended in order to bring global scholarly communication workflows a step forward. A service tells “this thing from this identifier system is the same as that thing from the other identifier system” (without in getting into any philosophical details)
This means in practice that for example a researcher who moves from one country to another, to work in another research institute, can be identified as the same person. This about this person can be said that he/she has worked on these research projects that are registered in these separate systems, and has published these scholarly works in these separate journals form these different publishers, has written these web log items, repositories and has produced these datasets.
For the action plan that is presented to the funders (a link will be provided as soon as the report is finished) we have concentrated on 4 categories of identifiers that needs serious up-take in order to support a global scholarly communication infrastructure. These categories are identifiers for “organisations”, “repositories”, “objects” and “people”. An equivalence service tells the equivalence between two things within a identifier category.
[iframe http://prezi.com/17905/view/ 500 400]
Further on the presentation.
- “Organisations” can have identifiers, we considered the DNS registry as a starting point. More identifier systems might exist, and we use the equivalence service to bind the organisation identifiers. Organisations might emerge, dissolve, split and merge with one another, the equivalence service must take that into account.
- “Repositories” can also have identifiers, we considered to use ROAR or DOAR to use as a starting point registry. However for complete coverage of the scholarly communicationsworkflow we must build a registry that not only contains Open Access repositories (like ROAR and DOAR does). Furthermore the repositories runs on Self-populating and automatically de-populating mechanisms. And just like organisations the repositories might emerge, dissolve, split and merge with one another, the equivalence service must take that into account.
- For “Objects” also many registires exist like DOI, Handle, URN:NBN, ARK, etc. On the level of the bitstream (Manifestation level in FRBR terms) an MD5 hash match might to the trick in order to tell the equivalence between identifier systems. E.g. this publication in that repository using Handles is the same as that publication in that repository using URN:NBN. This is phase 1 in the action plan. Phase 2 is to make equivalence on the Expression level in FRBR terms. For textual publication this can be done by using methods used in plagiarism detection software, where the statistical proximity is measured. E.g. the version of this publication at the publisher is the same as this author version in this repository. (a possible service can be made where the end-user can choose between these versions he/she would prefer to read / gain access to. The
- “People” identifier was originally called “Author” identifier, but we decided to make it mote general and considering the role as a property of a person. This we did because a researcher might take effort in the research process (contributing data to a dataset using measurement equipment), but might not always write something as an author. People cannot be merged or split, but can have many identifiers when participating in different systems, wear different roles and use different persona’s. For example a researcher has a Thomson Researcher ID and write under different persona’s depending on the journal he/she is writing on, also she/he might use different names due to marrial structures that can differ in different countries, also he/she has a Scopus ID, a Crosref ID, a Dutch DAI, a ISNI (ISO Name ID), a Linked-in account, an Open ID account with different persona’s, a Campus login, a national federated login (SURFfederatie), an ID in several CRIS systems because he/she is working part-time at different universities under different roles, etc. A meta-service must be build to ensure the global equivalence and non-equivalence of a person in order for systems to know this is the same person it is dealing with. The service is self-populating, where the person can say: “is is who I am also” and “this is who I am sertainly not”. Services like this already exist like www.danyid.org where a person can claim or tell the system the Identities he/she has got. Since Dandy ID is a popular web2.0 service for socialnetworks, it is possible to add identity management services, which is commercially very interesing for these social networks.
Thoughts: The way I see it is that the meta-identifier-structure is a loosely-coupled structure where RDF stores are globally distributed, where each store tells a part of the story. For example in one store the equivalence of the ID of a person of the login on Campus A is binded with the ISNI of that person. Another store contains the bindigns between the ISNI and Linked-in Accounts. And in another store the bindings between the Dutch DAI and the linked-in acount is stored. So one can list a list of publications that are binded with a Dutch DAI using the login of Campus A. Is there any persistency? Well, if there are many stores making a lot of different binding the path can be re-routed, if not there we have a problem. In order to create a stable infrastructure, terms like LTP policy, Contracts and Service level agreements should be used… (the knowledge exchange project, see below, should provide a partial answer to that.)
Thoughts: What we left out of scope is to bring this into a broader perspective where an equivalence service is nothing more then a relationship service, where the relationship is named between two things. In this perspective the predicate “is equal to” is just a term of two things that are representing the same thing or concept. Making it more generic it could contain many more predicates like “is cited by”, “works at”, “is owned by”, etc. A generic approach might not only make semantic relationships within an identifier category, but between identifier categories aswell. The people of the citation workshop might be interesing in utalising this service where then “cited from” relationships can be stored across identifier systems on a meta-level in a global interoperable fashion.
Knowledge Exchange – URN:NBN based Persistent Identifier Infrastructure pilot
On Monday afternoon I gave a presentation about the Knowledge Exchange project that promotes and implements a robust and sustainable identifier and resolution infrastructure for permanent access to knowledge assets for science and cultural heritage that is sustainable for the long term.
[iframe http://prezi.com/17406/view/ 500 400]
Knowledge Exchange – URN:NBN based Persistent Identifier Infrastructure pilot (new window)
Yes this is just yet another identifier mechanism, but the special thing here in this project is that it is a joint cooperation of National players who already have URN:NBN mechanisms in place and want to team-up. This project is not about technology, because it is already there, this project is about policy making on how to create an infrastructure that is robust, sustainable organisation model and that provide access to scientific and cultural heritage for over a long period of time.
The outcome of the project is a LTP policy for global registration and resolution of URN:NBN’s. The project group will define a set of roles and a set of responsibilities that must be effectuated by these roles. This policy will adopt most likely something like www.datasealofapproval.org.
More about this project can be found here: www.surfgroepen.nl/sites/surfshare/public/pid/
Just some thoughts:
Although the project has not been started, I can imagine that the a policy rule could be: “If you want to use URN:NBN numbers to identify your knowledge assets, you must have a working LTP strategy in place”. In practice this means that if you have a repository in the Netherlands and you want to join the global URN:NBN identification and resolution network you have to let all your URN:NBNed documents store in the National Library LTP eDepot. The National Registration Agency is the only party that can distribute and register URN:NBN prefixes. When the repository is registered they have to provide a OAI-PMH feed that contains the URL’s of the documents in the repository and the URN:NBN identifiers. The URL-URN bindings are stored in the national resolver and the files are copied to the eDepot. The URL of the eDepot file is binded to the URN in the resolver as a “backup” location.
When I was talking to Jonathan Rees (Science Commons) an idea popped into my mind that this mechanism can be extrapolated in order to form a LOCKSS principle (Lots of copies keep stuff safe). The mechanism to copy files to the eDepot, can also be used to copy the files to other Dutch repositories. One URN identifier contains lots of URL’s of the mirror duplicates at other repository locations. This also can be a mandatory policy rule that in the end needs to be enforced in a technical manner, and very possible to build already in the Netherlands.
The only thing is that the Dutch eDepot has a LTP strategy that folows two LTP methods 1. strip the text to simple ASCII text, and 2. keep the files migrating to the most current version of the format. This is expensive and the repositories have a too small budget to use similar methods. So after a this thought experiment the LOCKSS principle is not a very safe way to guarantee readibility over a long period of time. (bing!) Except when the eDepot is synchronizing the repositories by feeding back the most current version of the data format. The advantage is that 1. the enduser can always read the most current version of the dataformat, and 2. the end-user does not have to use the slow tape-machined eDepot access to read the most current dataformat, but can use the high performing repository systems to gain faster access to the most current version. All thanks to the URN:NBN resolver that redirects the user to the most appropriate *default* location.
And just a side note: A presentation of Juha Hakala about the 7 levels of identification:
Libraries, Collections, Authors, Works, Manifestations, Components, Queries. More on http://pid.ndk.cz/dokumenty/zakladni-literatura/Persistent_identifiers_elag2005.ppt
-
infrastructuur voor het wetenschappelijke informatie domein
hier komt een stuk over infrastructuur
Het gaat over de motivatie waarom we nou zo nodig moeten veranderen, is er een besef van urgentie?
kernwoorden kunnen zijn:
- infrastructuur, standaarden
- diversiteit aan diensten
- wetenschap op de dag van vandaag is conservatief
- wat weten wetenschappers over wetenschapsdynamica en wetenschapsprocessen zelf
- kort overzicht van de geldstromen
- geen systemen die een probleem oplossen waardoor dubbele informatie in dubbele formulieren moet worden ingevuld… redundantie vermijden, dus moet er opnieuw gekeken worden naar het totaalplaatje van het proces.
- besef vanurgentie: is “open access” het verhaal waarbij we moeten inhaken om een efficientere kennis cultuur te krijgen.
- hoe krijg je verandering in de cultuur verankerd? Wat is de rol van de jonge onderzoeker in deze? (is nieuwsgierig naar iets nieuws: iets voor promovendi netwerk nederland?) Wat is de rol van de gevestige onderzoeker? (hoeft zich geen zorgen te maken over zijn reputatie, kan resources vrijmaken binnen zijn vakgroep om te werken aan wetenschapsdynamica)
- urgentie: de manier waarop wetenschappers worden afgerekend moet veranderen.
- wat moet de infrastructuur bieden?.. standaarden, application program interfaces, een bibliotheek van deze koppelvlakken, semantische betekenissen aan ontologische elementen.
- welke diensten kunnen ontwikkeld worden, case studies.

